Trabajando con Puppet
Aquí seguimos hablando de la herramienta Puppet. En ésta parte, ahora que tenemos tanto el servidor como el cliente configurado, y ambos conectados, veremos algunos ejemplos de funcionamiento, que a fin de cuentas es lo realmente interesante.

Manos a la obra con Puppet
Antes de continuar vamos a recapitular, hasta ahora hemos hablado de que era y en qué consistía el producto, además de su instalación en un servidor con CentOS. En la segunda parte vimos la instalación del agente en un servidor Debian. Bien, una vez puestos en antecedentes, continuemos.
¿Cómo se recogen los datos?
Puppet reúne todos los datos de cada uno de los nodos, de momento nosotros sólo tenemos uno, con una herramienta llamada Facter. Dicha herramienta, por defecto, reúne información útil para la configuración del sistema, por ejemplo, nombres de sistemas operativo, nombre de host, direcciones IP, claves SSH, etcétera. En cualquier caso también es posible añadir datos personalizados que no son parte del conjunto por defecto.
Los datos reunidos por Fact pueden ser útiles en muchas ocasiones. Por ejemplo, se puede crear una plantilla de configuración de un servidor web y rellenar automáticamente las direcciones IP adecuadas para un host virtual determinado. O bien determinar si un servicio web como Apache2, en CentOS se llamaría ‘httpd’. Son ejemplos básicos, claro, pero nos puede dar una idea del funcionamiento.
Si queremos ver una lista de ‘facts’ que se están ejecutando automáticamente en el nodo agente, escribimos:
/opt/puppetlabs/bin/facter
De esta manera veremos todos los datos recolectados, en la imagen podemos ver un extracto:
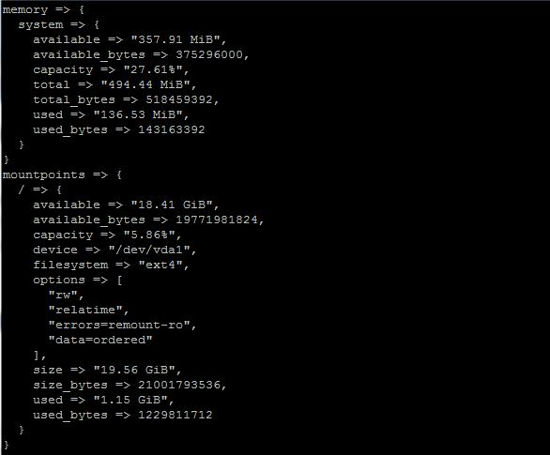
Los manifiestos
El producto utiliza una lenguaje de dominio específico para describir las configuraciones del sistema, y estas descripciones se guardan en archivos denominados ‘manifiests’, con extensión de archivo .pp El archivo de manifiesto principal por defecto se encuentra en el servidor maestro, en la ubicación /etc/puppetslabs/code/environments/production/manifiests/site.pp Vamos a crear un fichero vacío utilizando ‘touch’
touch /etc/puppetlabs/code/environments/production/manifests/site.pp
El fichero ya os he comentado que está vacío, por lo que de momento no afectará al nodo cliente.
¿Cómo ejecutamos el Manifiesto Principal?
En agente de Puppet comprueba de manera periódica la conexión con el servidor maestro, generalmente cada treinta minutos. Cuando realiza dicha tarea envía los datos sobre sí mismo al servidor principal, y utilizará el catálogo actual, esto es, una lista compilada de recursos y sus estados deseados, que son relevantes para el agente, determinados por el manifiesto principal. El nodo cliente intentará entonces hacer los cambios apropiados para alcanzar el estado deseado. Dicho ciclo continuará siempre que en el servidor maestro Puppet se esté ejecutando.
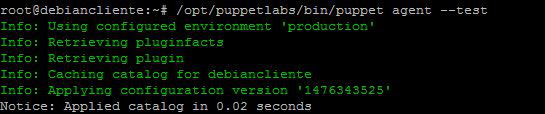
Dicha comprobación también se puede hacer de manera manual, de la siguiente manera, desde el cliente:
/opt/puppetlabs/bin/puppet agent --test
Con el resultado:

Ejemplo de Manifiesto
Recordamos que el manifiesto principal está ubicado en:
/etc/puppetlabs/code/environments/production/manifests/site.pp
Para editarlo podemos utilizar nuestro editor favorito, en mi caso ‘nano’, a modo de ejemplo, añadimos las siguientes líneas:
file {'/tmp/example-ip': # tipo de recurso y nombre de fichero
ensure => present, # se asegura de que exista
mode => '0644', # permisos del fichero
content => "Esta es mi direccion publica: ${ipaddress_eth0}.\n", # direccion publica ipaddress_eth0 fact
}
De esta manera creamos un fichero, si no existe, con el contenido del texto con nuestra IP pública.
Guardamos y salimos del fichero. Los comentarios son sólo para dar sentido a la información, no afectarán a la ejecución. Así todos nuestros nodos tendrán dicho fichero con la información de su IP pública, con los permisos indicados. Podemos esperar hasta que el agente se ejecute, o de manera manual, tal y como hemos visto antes. Podemos comprobar que efectivamente se ha creado el fichero:
cat /tmp/example-ip
Si todo ha ido bien veremos el resultado del texto más la IP
Utilizando módulos

En el apartado vamos a utilizar módulos, muy útiles para agrupar tareas. Hay muchos módulos disponibles en la comunidad Puppet, si queremos podemos escribir el nuestro.
Vamos a utilizar el módulo para el servidor web Apache, llamado ‘puppetlabs-apache’ desde ‘forgeapi’, de la siguiente manera, desde el servidor maestro:
/opt/puppetlabs/bin/puppet module install puppetlabs-apache
En la imagen podemos ver el proceso:

Ahora editamos el fichero site.pp, y añadimos:
node 'debiancliente' {
class { 'apache': } # utilizamos modulo apache
apache::vhost { 'pruebas.ochobitsunbyte.pw': # definimos el nombre del vhost
port => '80',
docroot => '/var/www/html'
}}node default {}
Una vez acabada la edición guardamos y salimos. Lo mismo de antes, o esperamos al proceso desde el maestro o bien lo forzamos desde el cliente con:
/opt/puppetlabs/bin/puppet agent --test
Veremos una larga lista de procesos en pantalla, si vemos letras en verde todo el rato, es que todo va bien 🙂
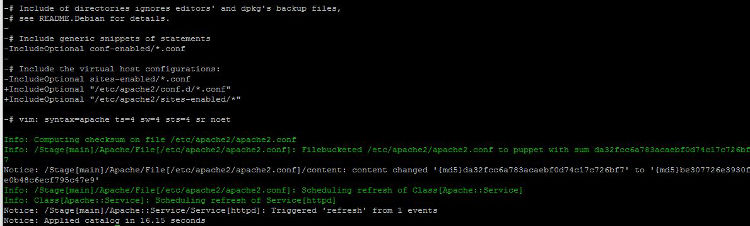
Y sí amigos míos, nos ha instalado todo!! Imaginaos que tenemos cien o mil nodos y queremos realizar una instalación en todos ellos, con Puppet lo conseguiremos en unos pocos pasos!! No hace falta decir las ventajas que tiene.
Pues nada, espero que la serie de artículos sobre éste producto os haya parecido interesante. Nos leemos en la próxima 😉
Fuentes | DigitalOcean


Muy bueno el tutorial. Gracias por compartirlo.
https://github.com/gurumelo/rantamplanti
Gracias a ti por pasarte por aquí y comentar. Un saludo