Conociendo las expresiones regulares (primera parte)
En la entrada de hoy, como primera parte sobre el tema, vamos a hablar sobre las expresiones regulares y los símbolos que utilizan. Como seguramente ya sabrás las expresiones regulares son utilizadas conjuntamente con muchos comandos de GNU/Linux y sistemas UNIX; incluidos comandos populares como awk, sed o grep, pero también otros como ed o ex, y en menor medida el editor vi. Las expresiones regulares son una forma coherente de especificar los patrones que se van a buscar
Unas de sus usos más habituales son utilizarlas para la sustitución de nombres de archivo. Por ejemplo, podemos utilizar el asterisco (*) que especifica cero o más caracteres para coincidir, el signo de interrogación (?) para especificar cualquier carácter y la construcción especifica […] para indicar cualquier carácter encerrado entre corchetes. Aunque estas distan bastante de las expresiones regulares más formales, que veremos más adelante.
La mejor manera de decir es hacer, por lo que veamos algunos ejemplos.

Que coincida con cualquier caracter
Un punto en una expresión regular coincide con cualquier carácter, sin importar cuál sea. Por ejemplo:
m.
Todas las coincidencias que contengan m y que vayan seguidas de cualquier carácter.
En cambio, con esta expresión regular:
.M.
Coincidirá con una M que está rodeada por caracteres cualesquiera, no necesariamente iguales.
Para probar las expresiones regulares podemos utilizar el editor ed, un editor de línea de comandos, que esta presente en GNU/Linux desde sus inicios.
¡IMPORTANTE!, para salir del editor ed simplemente tenemos que escribir «q» y apretar la tecla «ENTER«
Por ejemplo, al utilizar el editor ed y utilizar:
/…/
Busca hacia delante en el archivo que estás editando la primera línea que contiene tres caracteres cualesquiera rodeados de espacio en blanco.
Si no estás familiarizado con ed, si lo utilizas contra un fichero, te dirá primero el número de caracteres que tiene el fichero:
pi@raspberrypi:~ $ ed debian.txt 1371
A continuación, si utilizas print(p) puedes utilizar un prefijo con un indicador de rango, siendo el más básico 1, $, que es de la primera línea a la última del archivo:
1,$p
Para esta entrada vamos a utilizar como fichero de ejemplo un documento txt, con los primeros párrafos en castellano del manifiesto Debian:
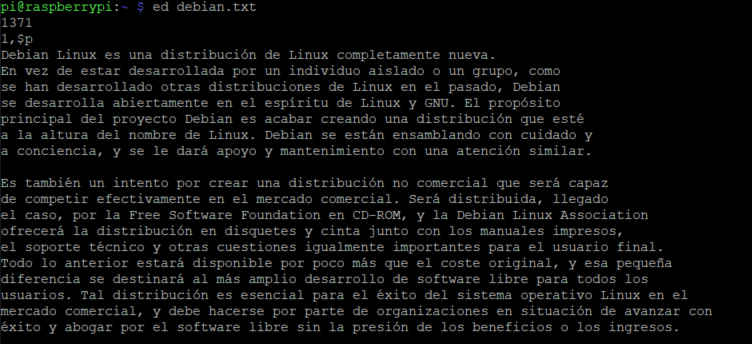
Fichero para trabajar con las expresiones regulares
Ahora que ya tenemos nuestro fichero de trabajo, vamos a empezar a probar las expresiones regulares.
/.../ Debian Linux es una distribución de Linux completamente nueva. / En vez de estar desarrollada por un individuo aislado o un grupo, como
En el ejemplo anterior ha buscado tres caracteres rodeados de espacios en blanco. Y a continuación repetimos la última búsqueda.
1,$s/libre/LIBRE/g 1,$sp
Esta substitución os sonará si habéis trabajado son sed, ya que cambiamos todos las coincidencias que sean igual a «libre» por «LIBRE»

Substituimos texto con expresiones regulares
Veamos un poco con detalle lo que hemos hecho. En la primera búsqueda, ed comenzó a buscar desde el principio del archivo y encontró que la secuencia «una» en la primera línea coincidía con el patrón indicado y lo imprimió.
La repetición de la búsqueda (el comando de ed /) resultó en la visualización de la segunda línea del archivo porque «por» coincidía con el patrón. Con «s» sustituimos el texto «libre» por «LIBRE» Con «1,$» indicamos que el patrón se tiene que aplicar a todas las líneas hasta el final del fichero, la sustitución sigue la estructura «s/viejo/nuevo/g«, donde «s«indica la substitución, las barras delimitan el viejo valor del nuevo, y con «g» indicamos que deben aplicarse el cambio tantas veces como sea necesario para cada línea.
Que coincida con el comienzo de la línea
Cuando el caracter (^) se utiliza como primer caracter en una expressión regular, coincide con el comienzo de la línea. Entoncex la expresión regular:
^Debian
Coincide con los caracteres «Debian» solo si aparecen al principio de línea. Esto en realidad se conoce como «raiz izquierda» en el mundo de las expresiones regulares.
/^Debian/ Debian Linux es una distribución de Linux completamente nueva.
Esto también nos permite cosas interesantes, como añadir contenido al principio de cada línea:
1,$s/^/>>/ 1,$p
Con un resultado como el que sigue:
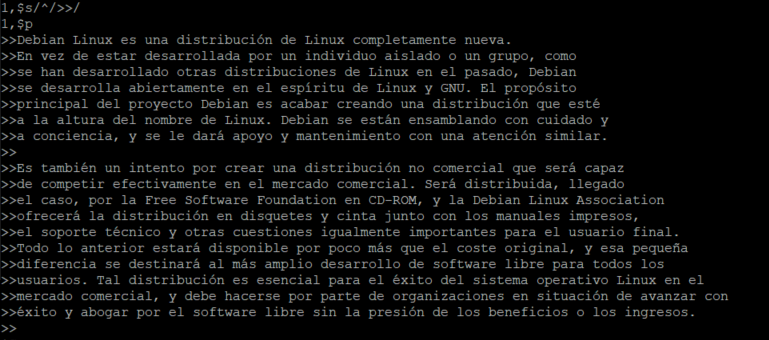
Ejemplo de substituir texto al principio de las líneas
En el ejemplo anterior también vemos cómo se puede utilizar una expresión regular (^) para hacer coincidir al comienzo de la línea. En este caso para insertar los caracteres «>>» al comienzo de cada línea. Lo podemos dejar como estaba de la siguiente manera:
1,$/^>>// 1,$p
Con el resultado:
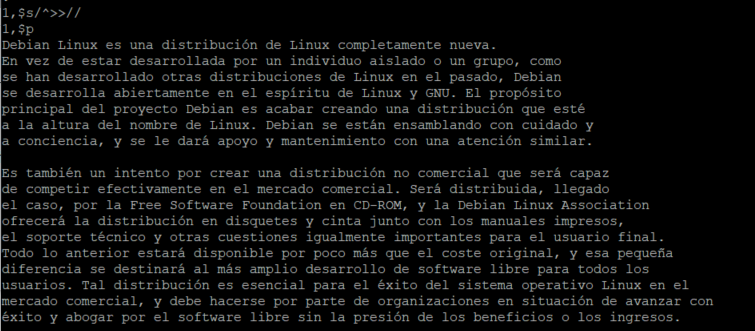
Dejamos el texto como estaba antes de aplicar la expresión regular
Coincidir con el final de la línea
Así como (^) se usa para poincidir con el comienzo de la línea, el signo de dólar ($) se utiliza para coincidir con el final de la línea. Con la expresión regular:
contenido$Esto hará que coincida con el contenido de los caracteres solo sin los últimos caracteres de la línea. Por ejemplo, con esta expresión regular:
.$Recuerda que el punto coincide con cualquier caracter, por lo que al aplicar esta expresión regular, esta coindiriá con cualquier caracter al final de la línea, incluido el punto.
Pero entonces, ¿cómo lo haremos si queremos coincidir justamente con un punto al final de la línea? Por norma general, si queremos que coincidan con alguno de los caracteres que tienen un significado especial en las expresiones regulares, debemos preceder el caracter con una barra invertida (\) para anular su significado especial, por ejemplo:
\.$
De esta manera coincide con cualquier línea que termine en un punto, y con la expresión regular:
^\.
Coincide con cualquier línea que comience con un punto.
Si queremos rizar el el rizo y queremos especificar una barra invertida como un caracter real, debemos utilizar dos barras invertidas seguidas (\\)
Veamos algunos ejemplo con el texto que estamos utilizando:
/\.$/
De esta manera listamos la siguiente línea que acabe con punto.
1,$s/$/>>/ 1,$p
Añadimos (>>) al final de cada línea.
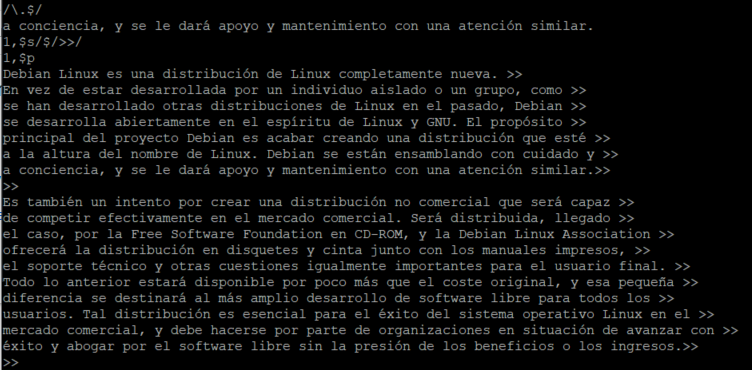
Ejemplo de uso de $ en las expresiones regulares
Otro uso muy habitual de (^) y ($) como expresión regular es:
^$
De esta manera indicamos que coincide con cualquier línea que no contenga ningún caracter. No confundir con:
^ $
Que coincide con un solo espacio.
Y por hoy lo dejamos aquí. En la siguiente parte veremos más expresiones regulares típicas, ya que la entrada ya ha quedado algo extensa.


Comentarios Recientes